Hadoop
Hadoop adalah salah satu software open-source dari Apache yang di rancang untuk pemrograman secara kluster, bermanfaat untuk distribusi data dan memproses data berukuran besar atau big data. Jadi efisiensi dari pada memproses data menggunakan satu komputer, pemrosesan bisa digunakan beberapa komputer yang sudah terinstall hadoop. Penganalisisan data bisa dilakukan menggunakan data terdistribusi pada komputer yang telah terinstall hadoop, menghasilkan proses yang lebih efisien.
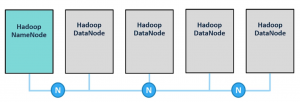
Kluster Hadoop terdiri dari ‘NameNode’, backup dari ‘NameNode’, dan beberapa node berisi data. Masing-masing node pada kluster memiliki memory, CPU, dan disk storage. Node pada kluster dapat ditambah kurangi sesuai kebutuhan.
Ada tiga komponen utama pada Hadoop yaitu, HDFS, Yarn, dan MapReduce. Komponen tersebut akan memproses pembacaan, penulisan, dan pemrosesan data secara otomatis. Berarti programmer dapat menulis progrram untuk mengolah data pada satu komputer dan terdistribusi melalui Hadoop.
Hadoop memiliki beberapa fitur utama yang membuatnya sangat menarik sebagai bagian dari solusi teknologi big data. Misalnya: sistem Hadoop mudah untuk digunakan, open-source, dan penyimpanan yang terdistribusi, menyebabkan biaya untuk operasional yang rendah. Data tereplikasi di beberapa node untuk membuatnya toleran terhadap kesalahan. Hadoop mendukung pemrosesan paralel, cocok untuk melakukan analisis pada volume data yang sangat besar. Dan Hadoop mudah diskalakan. Ini diskalakan dengan baik untuk menangani sejumlah besar data, dan mudah diperluas dengan menambahkan lebih banyak node penyimpanan ke dalam kluster.
SAS memiliki poin integrasi yang membuat penggunaan Hadoop tidak terlalu asing. Pernyataan LIBNAME, prosedur SAS, dan transformasi Data Integration Studio adalah beberapa contoh integrasi SAS yang dapat digunakan untuk berinteraksi dengan Hadoop.
HDFS
Ada tiga modul inti pada Hadoop:
- Hadoop Distributed File System, atau HDFS adalah sistem file virtual yang digunakan untuk mendistribusikan file di seluruh kluster Hadoop.
- YARN adalah sistem yang menangani permintaan pekerjaan, meluncurkan pekerjaan atau menempatkan permintaan pekerjaan dalam antrian, dan mengalokasikan penggunaan sumber daya dalam klaster.
- MapReduce adalah modul yang menyelesaikan pemrosesan data paralel terdistribusi dalam HDFS.
Setiap file dalam HDFS didistribusikan di seluruh node data Hadoop dalam bentuk blok. NameNode berisi informasi tentang di mana data berada di setiap DataNode. Meskipun tidak digambarkan dalam diagram, data direplikasi dalam HDFS untuk mendukung toleransi kesalahan. Secara default, setiap blok file dalam HDFS direplikasi pada tiga node data lainnya. Jika ada DataNode yang down, data cadangan tersedia untuk digunakan.
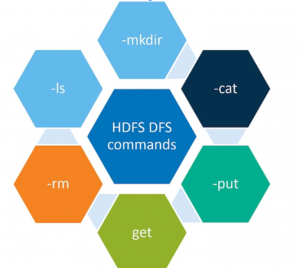
Salah satu cara pengguna dapat berinteraksi dengan HDFS adalah dengan mengirimkan perintah sistem file Hadoop dari prompt perintah Linux.
Contoh dari HDFS commands:
Map Reduce
Jika HDFS mengotomatiskan proses penyimpanan data terdistribusi, maka sistem MapReduce mengotomatiskan pemrosesan terdistribusi. Untuk setiap proses, sistem MapReduce mengoordinasikan serangkaian tugas yang dijalankan secara paralel di seluruh kluster. Proses MapReduce terjadi dalam tiga tahap: map, shuffle dan sort, dan reduce. Setiap proses melakukan operasi tertentu. Pada tahapan map menginisiasi pembacaan blok data dalam HDFS. Tahapan map juga menyelesaikan operasi perbaris data termasuk memfilter baris atau menghitung kolom baru dalam baris. Tahapan shuffle dan sort digunakan untuk mengurutkan dan mengelompokkan baris pada data yang diperlukan. Terakhir, tahapreduce digunakan untuk melakukan penghitungan akhir, termasuk menghitung statistik ringkasan dalam grup. Pada tahap reduce juga menulis hasil akhir data dalam bentuk HDFS.