Web Scrapping Dengan Python
Web Scrapping Dengan Python
Web Scrapping merupakan proses untuk meng-ekstrak informasi (teks) dari website dan halaman online. Merupakan metode untuk mengambil informasi serta dataset untuk di analisis lebih lanjut.
Kali ini kita akan mencoba untuk melakukan ekstraksi informasi menggunakan python serta library Beautiful Soup. Beautiful Soup merupakan library yang banyak digunakan untuk melakukan parsing elemen html. Sederhananya, library ini digunakan untuk menerjemahkan elemen tag html untuk diambil isi teks-nya.
Mari Kita Coba
Pada praktek kali ini, mari kita coba untuk meng-ekstrak informasi mengenai daftar episode anime Dragon Ball. Setelah mencoba mencari informasi mengenai daftar episode anime Dragon Ball, kita dapatkan bahwa informasi tersebut dapat diambil dari website wikipedia di link berikut https://en.wikipedia.org/wiki/List_of_Dragon_Ball_episodes.
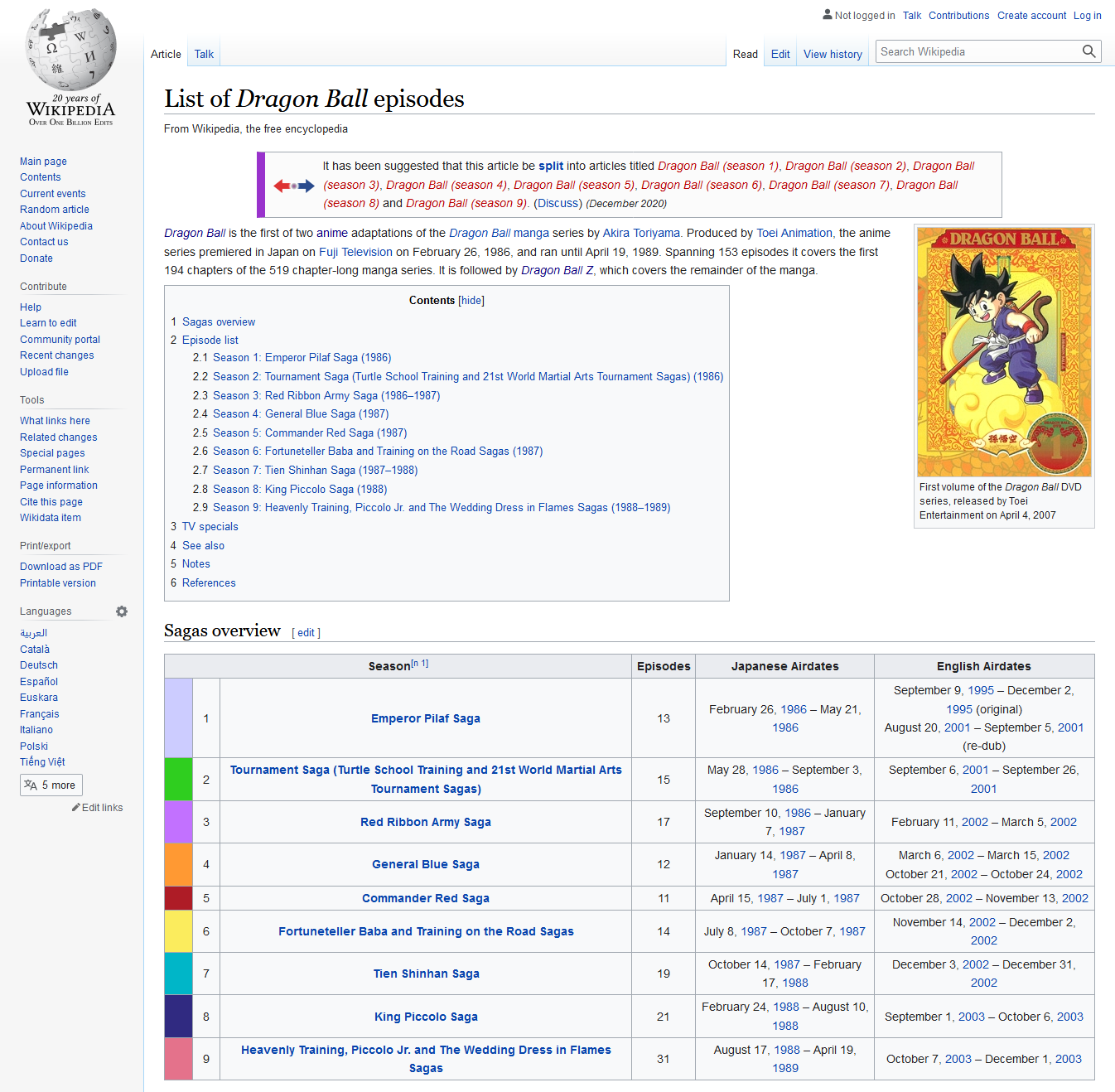
Dari sejumlah halaman yang ditampilkan, kita akan coba untuk meng-ekstrak tabel saga overview seperti gambar diatas.
Langkah Pertama
Pastikan library Beautiful Soup dan Request sudah terinstall, apabila belum jalankan perintah dibawah ini di console python. Library Requests berfungsi untuk mengambil elemen HTML dari sebuah alamat website yang diberikan, dan ini akan menjadi input bagi Beautiful Soup untuk melakukan parsing halaman.
pip install beautifulsoup4
pip install requests
Setelah berhasil menginstall dua library diatas, lakukan import library untuk menguji apakah library tersebut sudah terinstall dengan baik dan selanjutnya bisa kita gunakan dalam kode python kita.
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
Langkah Kedua
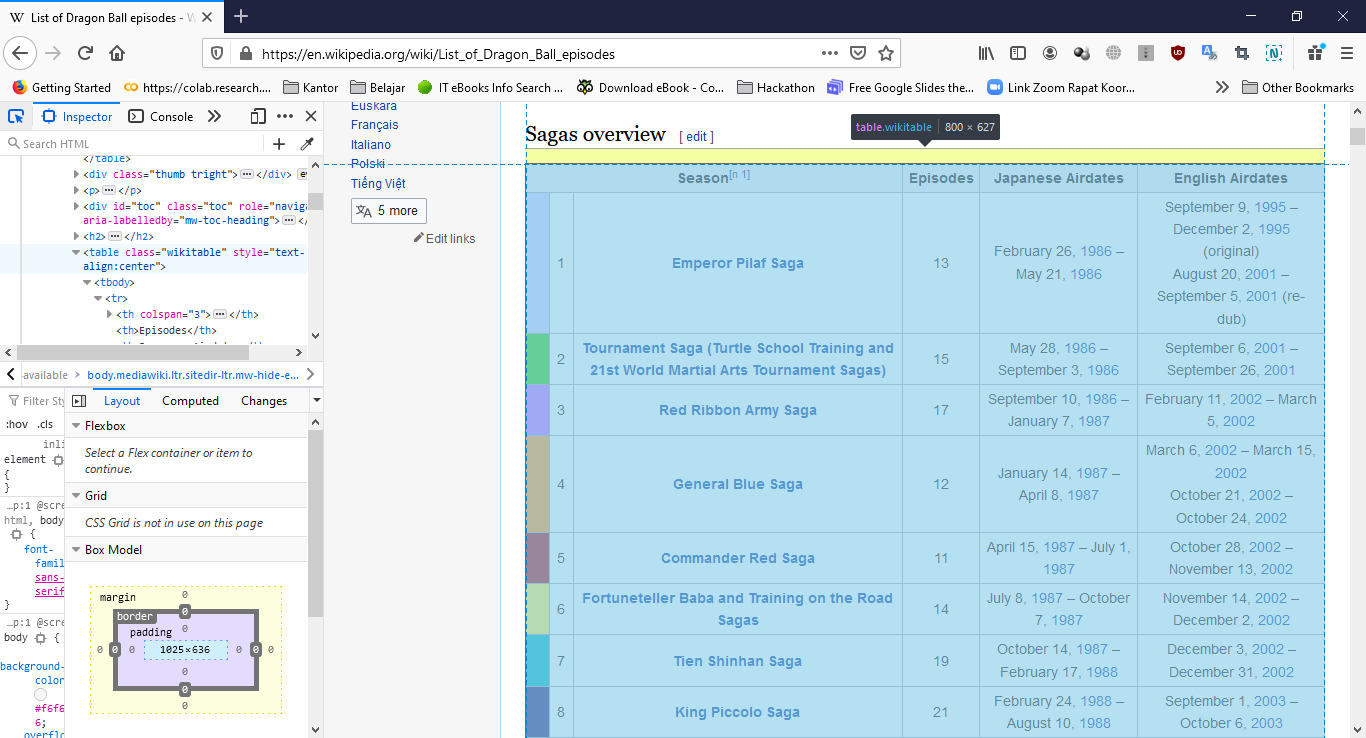
Lakukan pengecekan melalui browser, pada elemen manakah tabel yang akan kita akstrak tersebut berada. Apabila menggunakan Firefox/ Chrome tekan CTR+Shift+I atau dengan melakukan klik kanan pada mouse dan pilih Inspect Element.
Dari informasi yang ditampilkan pada jendela Inspect Element tersebut diketahui bahwa tabel yang akan kita ekstrak berada pada elemen table class=”wikitable”.
Langkah Ketiga
Setelah mengetahui di elemen mana informasi tersebut akan diambil, saatnya kita melakukan pemanggilan dan ekstraksi dari halaman tersebut. Panggil halaman menggunakan library request:
alamat = "https://en.wikipedia.org/wiki/List_of_Dragon_Ball_episodes"
req = Request(alamat, headers={'User-Agent': 'Mozilla/5.0'})
Perintah diatas akan melakukan pemanggilan pada alamat wikipedia. Argumen headers digunakan agar panggilan kita seolah-olah berasal dari sebuah web browser (yaitu ‘Mozilla/5.0’). Argumen headers ini sifatnya opsional, beberapa website tidak mensyaratkan hal tersebut tetapi ada beberapa website lainnya yang melakukan pengecekan agar halaman website mereka hanya bisa dibuka menggunakan browser yang legitimate.
Langkah Keempat
Setelah halaman web berhasil dibuka, jalankan Beautiful Soup untuk melakukan ekstraksi tabel yang akan kita ambil.
html = urlopen(req).read()
data = BeautifulSoup(html, 'html.parser')
table = data.find_all('table', {'class': 'wikitable'})[0]
Variabel table menyimpan hasil pengambilan elemen tabel pertama yang merupakan tabel yang ingin kita ambil dari halaman website tersebut. Apabila kita coba tampilkan variabel tersebut penggunakan fungsi print maka akan menghasilkan tampilan seperti berikut:
print(table)
<table class="wikitable" style="text-align:center"> <tbody><tr> <th colspan="3">Season<sup class="reference" id="cite_ref-1"><a href="#cite_note-1">[n 1]</a></sup> </th> <th>Episodes </th> <th>Japanese Airdates </th> <th>English Airdates </th></tr> <tr> <td bgcolor="#CCF" width="3%"> </td> <td width="3%">1 </td> <td><b><a href="#Season_1:_Emperor_Pilaf_Saga_(1986)">Emperor Pilaf Saga</a></b> </td> <td>13 </td> <td>February 26, <a href="/wiki/1986_in_television" title="1986 in television">1986</a> – May 21, <a href="/wiki/1986_in_television" title="1986 in television">1986</a> </td> <td>September 9, <a href="/wiki/1995_in_television" title="1995 in television">1995</a> – December 2, <a href="/wiki/1995_in_television" title="1995 in television">1995</a> (original)<br/>August 20, <a href="/wiki/2001_in_television" title="2001 in television">2001</a> – September 5, <a href="/wiki/2001_in_television" title="2001 in television">2001</a> (re-dub) </td></tr> <tr> <td bgcolor="#2FCE1F"> </td> <td>2 </td> <td><b><a href="#Season_2:_Tournament_Saga_(Turtle_School_Training_and_21st_World_Martial_Arts_Tournament_Sagas)_(1986)">Tournament Saga (Turtle School Training and 21st World Martial Arts Tournament Sagas)</a></b> </td> <td>15 </td> <td>May 28, <a href="/wiki/1986_in_television" title="1986 in television">1986</a> – September 3, <a href="/wiki/1986_in_television" title="1986 in television">1986</a> </td> <td>September 6, <a href="/wiki/2001_in_television" title="2001 in television">2001</a> – September 26, <a href="/wiki/2001_in_television" title="2001 in television">2001</a> </td></tr> <tr> …
Selanjutnya kita akan coba simpan masing-masing baris dari tabel tersebut kedalam sebuah list bernama rows.
rows = table.findAll('tr')
Lakukan iterasi pada variabel row untuk memecah masing-masing kolom menjadi sebuah list yang kemudian disimpan kedalam variabel hasil.
hasil = []
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
hasil.append(cols)
Buat dataframe dari variabel list hasil dan tampilkan hasilnya.
df_hasil = pd.DataFrame(hasil)
df_hasil
Maka akan menghasilkan tampilan seperti berikut ini.
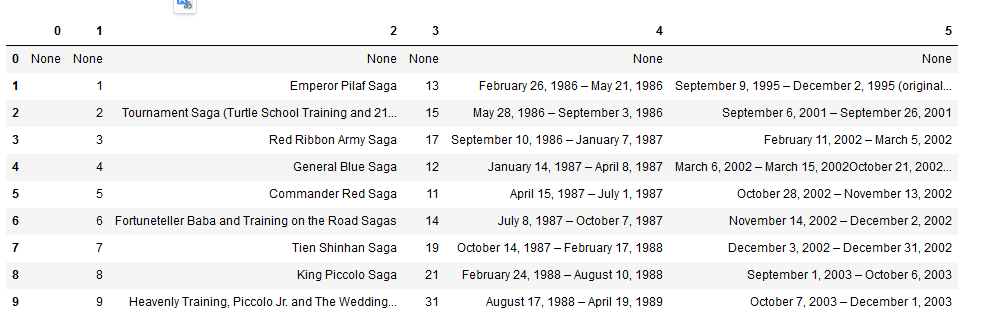
Sudah lumayan menyerupai data yang diambil dari wikipedia bukan? Tetap ada beberapa hal yang harus diperbaiki dari dataframe yang telah dihasilkan, pertama adalah hapus kolom satu karena tidak menyimpan informasi apapun. Kemudian selanjutnya adalah memberi judul masing-masing kolom dari tabel kita. Terakhir adalah menghapus baris awal dari tabel kita karena terlihat disana tidak memiliki data/ none.
Jalankan perintah berikut untuk melakukan 3 hal tersebut.
df_hasil = df_hasil.drop([0], axis=1) # menghapus kolom pertama
df_hasil = df_hasil.drop([0], axis=0) # menghapus baris pertama
df_hasil.columns = ['No', 'Season', 'Episodes', 'Japanese Airdates', 'English Airdates'] # memberi judul kolom tabel
Maka dari perintah diatas akan menghasilkan dataframe seperti gambar dibawah ini.
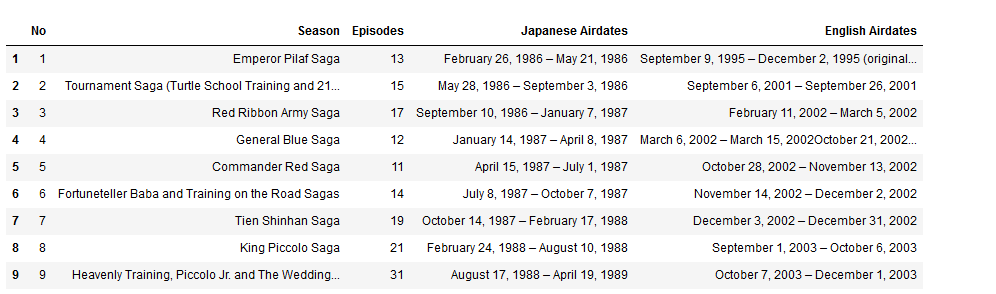
Coba bandingkan hasilnya dengan halaman website wikipedia.
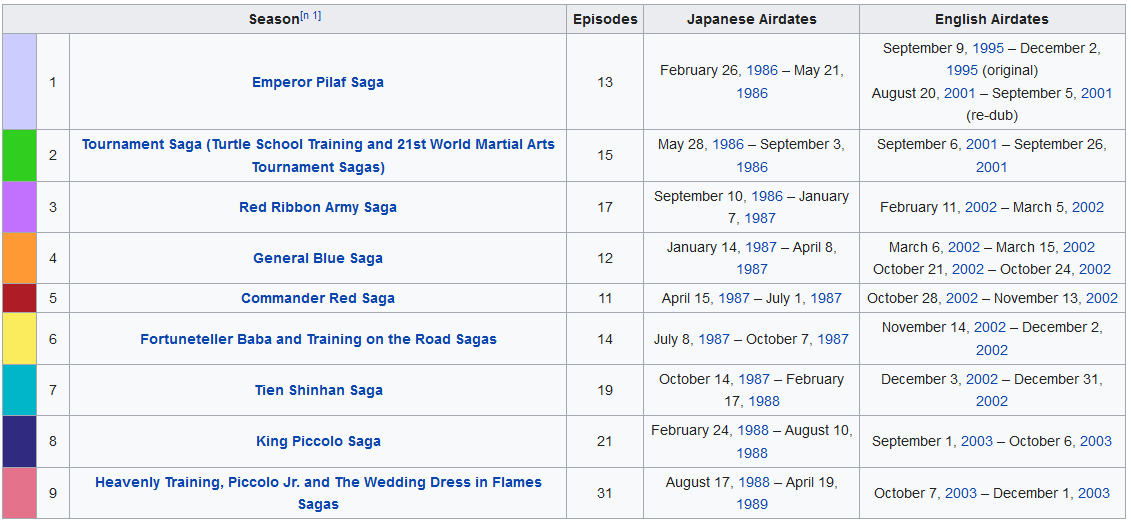
Langkah terakhir adalah menyimpan hasil tersebut kedalam file excel.
df_hasil.to_excel('data_serial_dragonball.xlsx', index=False)