
NLP Sederhana Dengan Python
Pada tulisan kali ini kita akan coba untuk melanjutkan bahasan tulisan sebelumnya mengenai wordcloud dengan python Membuat Wordcloud Dengan Python. Setelah sebelumnya kita mencoba untuk menampilkan kata-kata dalam sebuah tulisan sebuah berita dalam bentuk wordcloud, kali ini kita akan mencoba untuk melakukan plotting distribusi frekuensi kemunculan kata-kata dalam bentuk grafik.
Dalam praktek kali ini kita akan masih menggunakan dokumen pada tulisan sebelumnya, yang diambil dalam sebuah halaman website. Silahkan baca juga cara scrapping sebuah halaman web pada tulisan saya sebelumny disini Web Scrapping Dengan Python.
Pada tahapan kali ini kita juga akan memperkenalkan salah satu library python lainnya yang digunakan untuk melakukan ekstraksi kata dari sebuah tulisan/teks, library tersebut bernama NLTK dan Sastrawi.
Library NLTK dan Sastrawi ini akan digunakan untuk melakukan analisis terhadap dokumen yang dimiliki. Dalam prosesnya kita akan mengenal aspek dalam NLP (Natural Language Processing) yaitu tokenization dan stopwords.
Pada tahap akhir, kita akan memvisualisasikan hasil distribusi frekuensi pada kata-kata yang terdapat dalam sebuah teks/dokumen.
Lebih lanjut mengenai NLTK dapat dibaca-baca pada laman berikut https://www.nltk.org/, sedangkan Sastrawi dapat dibaca pada laman berikut https://pypi.org/project/Sastrawi/.
NLTK
NLTK adalah singkatan dari Natural Language Tool Kit, yaitu sebuah library yang digunakan untuk membantu kita dalam bekerja dengan teks. Library ini memudahkan kita untuk memproses teks seperti melakukan classification, tokenization, stemming, tagging, parsing, dan semantic reasoning.
Instalasi NLTK
Sebelum dapat menggunakan library NLTK ini, langkah awal adalah melakukan instalasi terlebih dahulu. Untuk melakukan instalasi NLTK pada python kita dapat memanfaatkan pip.
pip install nltk

lalu kita install semua library yang kita butuhkan,
python -m nltk.downloader popular
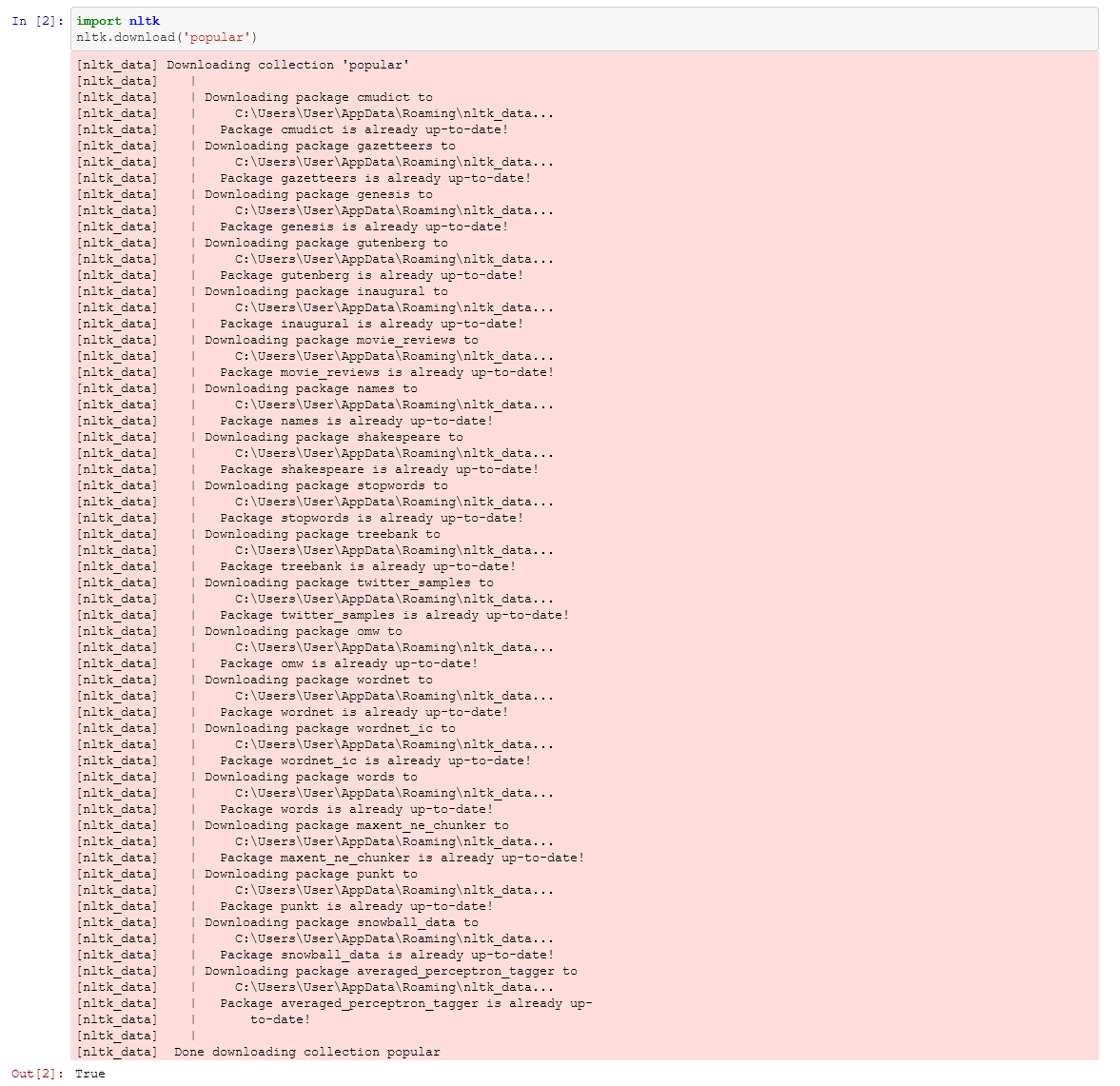
Sastrawi
Salah satu kekurangan dari NLTK adalah dukungannya terhadap bahasa Indonesia yang masih kurang, oleh karenanya kita akan menggunakan library tambahan berupa Sastrawi. Sastrawi adalah library NLP yang dikhususkan untuk bahasa Indonesia. Awal mulanya sastrawi dikembangkan dan diperuntukan untuk bahasa pemograman PHP, akan tetapi karena popularitasnya selanjutnya library ini dikembangkan juga agar mendukung bahasa pemograman Python.
Instalasi Sastrawi
untuk melakukan instalasi cukup dengan
pip install PySastrawi

Salah satu kelebihan Sastrawi yang tidak dimiliki oleh NLTK adalah kemampuan stemming dalam bahasa Indonesia.
Kita akan menggunakan library NLTK dan Sastrawi ini adalah untuk melakukan tokenisasi (tokenize) dan membuang stopwords dari teks. Tokenisasi merupakan proses untuk memecah isi dari teks menjadi kata-kata. Berikut contoh proses tokenisasi.

Proses selanjutnya adalah membuang stopwords. Mengapa stopwords perlu dibuang dari sebuah isi teks? stopwords sendiri merupakan kata umum dalam sebuah teks yang sebetulnya tidak memiliki makna seperti “yang”, “dan”, “di”, “dari”, dll. Berikut adalah beberapa stopwords dalam bahasa indonesia yang ada dalam library Sastrawi.

Import Library
Seperti biasa, langkah pertama kali ini adalah mengimpor library yang dibutuhkan.
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize import matplotlib.pyplot as plt
Setelah library yang dibutuhkan di import, langkah selanjutnya adalah membuka dan menyimpan teks yang akan diproses sebagai sebuah variabel.
f = open('berita_feb_unpad.txt', 'r')
isi_berita = f.read()
Kemudian kita coba memastikan apakah variabel teks tersebut sudah terisi dengan cara mencetaknya ke layar.
print(isi_berita)
Setelah variabel teks berhasil dibuat, langkah selanjutnya adalah melakukan tokenize teks tersebut. Dalam melakukan tokenize kita menggunakan fungsi word_tokenize() yang disediakan oleh library NLTK.
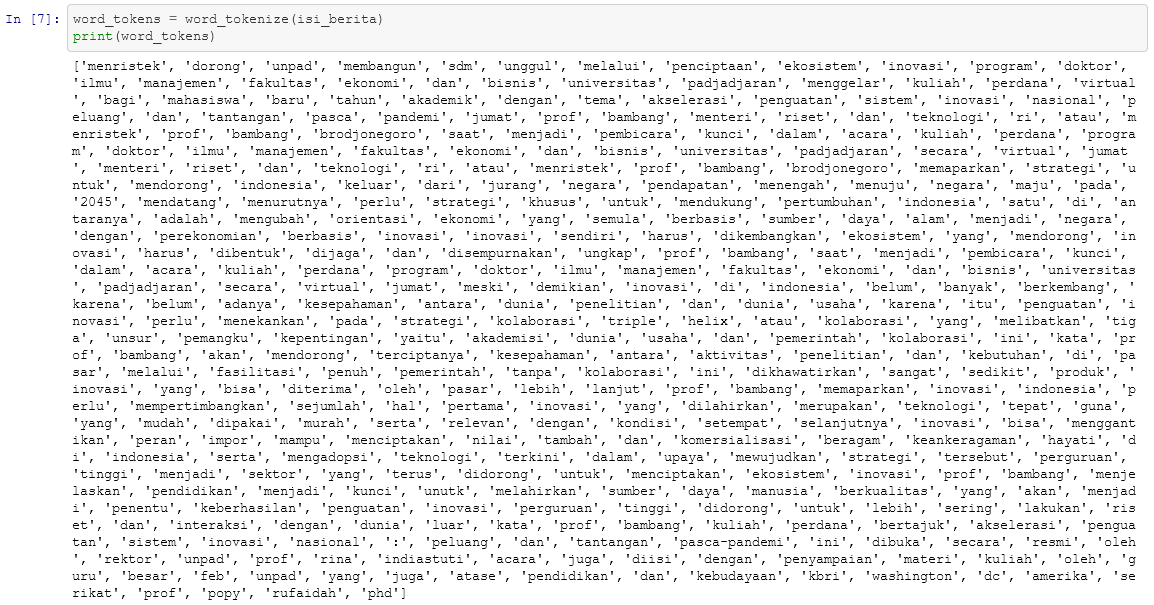
word_tokens = word_tokenize(isi_berita)
Setelah perintah diatas dijalankan, mari kita cek hasilnya dengan menampilkan ke layar.
print(word_tokens)
Kemudian dilanjutkan dengan membuang daftar stopwords dari teks.
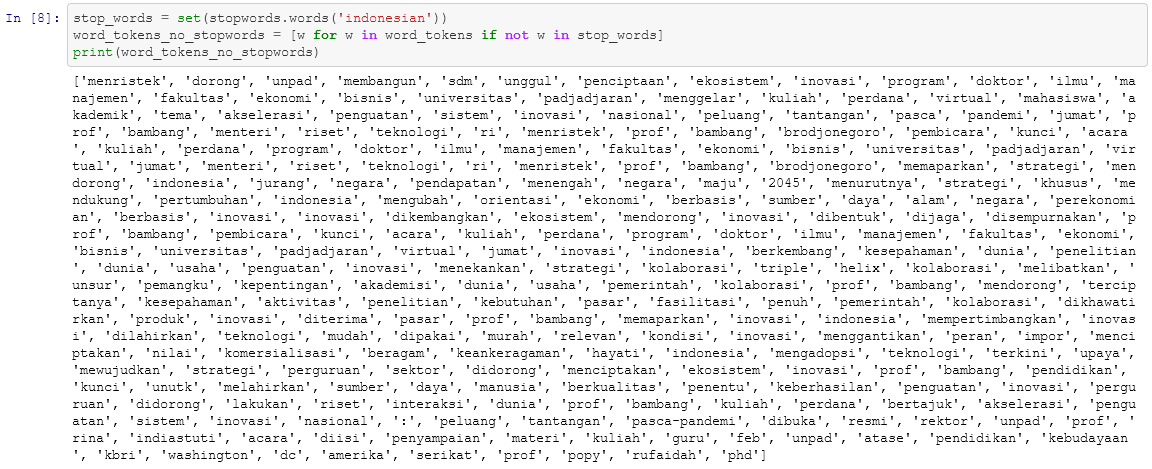
stop_words = set(stopwords.words('indonesian'))
word_tokens_no_stopwords = [w for w in word_tokens if not w in stop_words]
Kembali kita coba cek hasilnya dengan cara menampilkannya ke layar.
print(word_tokens_no_stopwords)
Distribusi Frekuensi Kata
Untuk melihat distribusi frekuensi dari masing-masing kata yang terdapat dari teks bisa menggunakan fungsi FreqDist() yang telah disediakan oleh NLTK. Berikut adalah caranya.
freq_kata_1 = nltk.FreqDist(word_tokens) freq_kata_2 = nltk.FreqDist(word_tokens_no_stopwords)
Pada kode diatas saya membuat 2 variabel yaitu freq_kata_1 dan freq_kata_2, hal tersebut dimaksudkan agar nanti kita bisa membandingkan hasil antara distribusi frekuensi teks yang telah dibersihkan dari stopwords dan teks yang belum dibersihkan dari stopwords.
Selanjutnya kita cetak hasilnya ke layar untuk menampilkan 20 kata yang paling banyak muncul dalam teks.
print(freq_kata_1.most_common(20)) print(freq_kata_2.most_common(20))

Visualisasi
Setelah mendapatkan daftar kata beserta distribusi frekuensi kemunculannya dalam teks, langkah terakhir adalah melakukan visualisasi hasilnya dalam bentuk grafik. Proses visualisasi ini dilakukan agar kita mudah untuk melihat hasilnya.
Kita dapat menampilkan distribusi frekuensi tersebut dalam bentuk grafik menggunakan bantuan library matplotlib.
freq_kata_1.plot(20) freq_kata_2.plot(20) plt.show()
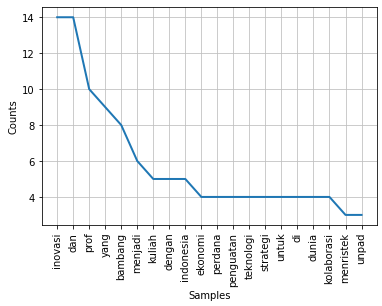
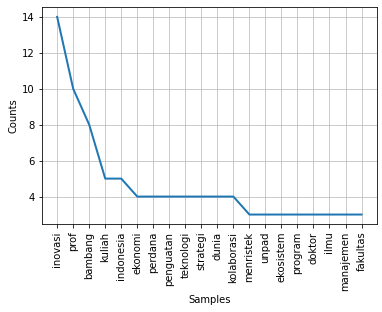
Bisa dilihat pada gambar grafik diatas, bahwa pada grafik pertama beberapa kata yang tidak memiliki makna (stopwords) seperti “dan”, “yang”, “di”, dll masih muncul dalam hasil grafik. Sedangkan pada gambar kedua, kata-kata tersebut sudah dibersihkan dan tidak muncul dalam grafik.
Akhir Tulisan
Seluruh bahan dan source code tulisan ini dapat diambil dalam link GitHub berikut https://github.com/jfanniw/Praktek-NLP-Sederhana.
