In the fourth week of Data Science EHASP, we did quite a lot of meeting to discuss new learning materials from dr. Mulya. The new learning materials are about databases and SQL. The meeting was held for 3 days which are on Monday (22-08-2022), Tuesday (23-08-2022), and Friday (26-08-2022). However, in addition to those meetings, I did another two meetings with my DataCamp group and dr. Budi to discuss our ongoing project. Those two meetings were held on Wednesday (24-08-2022).
Monday: Introduction to Database
In this meeting, the students, including me, were introduced to the term database which is quite familiar among college students like us. However, the term database that we know is only a collection of various data stored in some places (e.g., simple excel files) and it turns out that after the explanation given by dr. Mulya, we were quite surprised because a database is not just an ordinary collection of data, but it’s a collection of data that is well organized, and usually, each data corresponds to the others.
I believe that, a database is quite important for us to understand, especially when taking a survey. After all, it can make it easier for us to create a database, although it doesn’t have to be too detailed because it’s not related to medical science. I hope that we can understand this learning material very well and we can implement it later, especially when conducting research that uses quite a lot of data (big data).
Tuesday: Database Modelling
Following a database from the previous meeting, in this meeting, we continued to the second learning material, which is database modeling. We were provided by dr. Mulya with some methods to extract a collection of data, which is IFLS survey data collection, and convert it to a database. Those methods were handled in Microsoft Access, which is quite easy for us because no coding is necessary at all.
To my mind, we must understand database modeling, especially for data scientists because approximately, more than 50% of the data analysis process only consists of data extracting and data cleaning. Hence, this material will be very useful for us in conducting data analysis, especially in health research that involves a lot of data (big data).
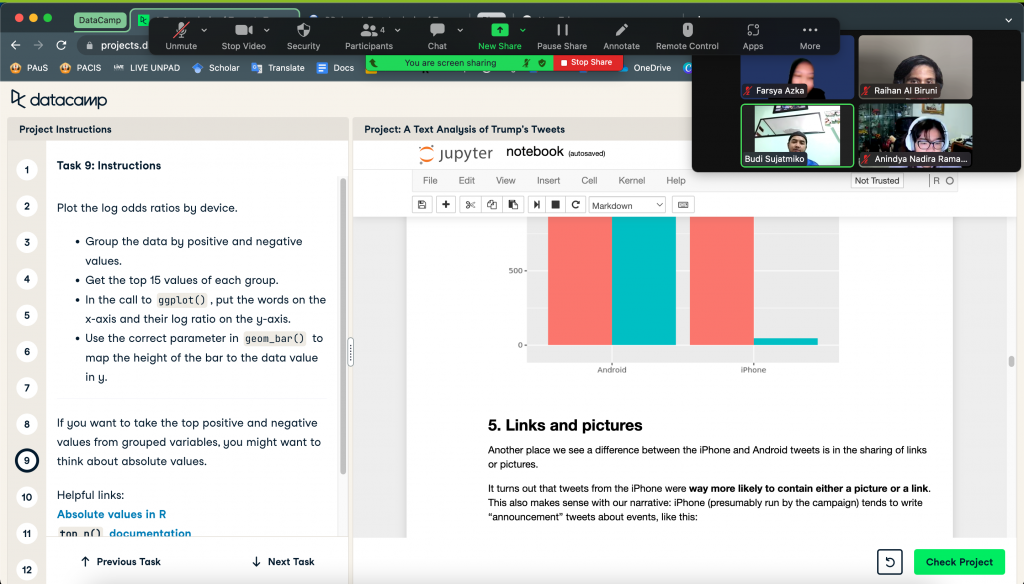
Wednesday: DataCamp Project
On this day, we, as a group 3, did two meetings, which are one meeting without dr. Budi and one meeting with dr. Budi. In the first meeting, which is the one without dr. Budi, we continued the progress of our DataCamp project that had previously worked on with dr. Budi.
We continued 7 tasks of the project which have previously been done in 2 parts from the initial part. Hence, we have worked on 9 parts of which the entire project part is 12 parts. As such, the process of working on the DataCamp project for our group is almost done.
We planned to do the remaining 3 parts of the project next in a meeting with dr. Budi at the same time to explain the process of each part of the project and the obstacles that we experienced before.
Through working on this project independently, I think it’s quite effective, especially to streamline the learning time from this EHASP which is quite short so that the material we study can be thorough. In addition, by doing the project independently, we can also explore any errors in the work process so that we can find solutions independently as well of course.
Nevertheless, I feel that what we need to pay attention to is the process of each part of the project. Each part of the project has various coding functions that have a certain purpose. Therefore, we need to understand each of these functions to be able to understand the essence of the project and its results and conclusions.
Friday: SQL
In this quite short meeting, dr. Mulya provided us with the last learning material regarding the database, which is the SQL or Structured Query Language.
If you want to export data from a database or create a database from your research data, it is obvious that you must be able to understand the programming language used in the database. In a database itself, the programming language used is SQL and it has a different syntax from R and Python that have been previously studied. Most of the syntax in SQL relates to functions for a table.
At this meeting, dr. Mulya provided us with an example of how to create a database using a MySQL application. However, the script of the database has been provided so that it only needs to be run and the table will be created. Then, we are asked to look at the design/model of the database that has been created so that we can understand the design/model of a proper database.
I believe that this material is quite important to understand, especially in the field of data science which is very closely related to databases. By understanding SQL and database modeling, we can make the data ecosystem neater so that it is easy to analyze.