
I had been explored plenty of new bits of knowledge and insights throughout my first year Elective Health Alliances Science Program (EHASP). The chosen course entitled Data Science and Big Data for Public Health brought me to another atmosphere of knowledge since I’m a medical student who only learns about science and barely knows about data science. Even so, once I finished the course, it kinda triggered me to develop some ideas or innovations regarding the topic of the course. Therefore, in this post, I will share my idea regarding data science in the medical field.
Introduction
Hoax originated from the term hocus to risk and is only involved in the e-Mail communication. However, generally, a hoax is every electronic message that contains deceptive information with intention of maliciously misleading anyone who receives it. The deceptive information can be shown as verbal, photo, audio, and/or multimedia content, such as fake virus warnings and photo manipulations.1
There are two motives for the hoax. One is commercial and the other is political. However, it also can be both commercial and political and can have an inferior impact, e.g., loss of reputation, material, and even life-threatening. So, it’s obvious that if a hoax rapidly spreads around the internet, the impact on an existing community will be rapidly too.2
Unfortunately, the spread of hoaxes is also assisted by social media, which accelerates the spread of news. Each day, there can be many hoaxes regarding the issues that occur in the world, such as the spreading of disease, conflict, and others.2 In 2018, a study reveals that hoaxes are disseminated faster on the Twitter platform than true stories. It’s due to people retweeting inaccurately.3 Hence, to my mind, it’s very important for us to know the characteristic of hoaxes, especially those hoaxes on the Twitter platform, to distinguish them from real information.
Methods
Throughout the EHASP course, especially from the DataCamp project (You can see my DataCamp project here), I learned two methods to analyze data from Twitter, which mostly contains verbal or textual data. Those methods are text mining and sentiment analysis. Using those methods, I expect that we can analyze data from Twitter with specific keywords, especially keywords in the medical field, e.g., Monkeypox, Covid-19, and so on. However, before we go to that topic, I will explain a little bit about text mining and sentiment analysis.
Text mining or also called text analysis and text analytics is a method to gain information from text by recognizing patterns and trends. The process of text mining can be through lexical resources, annotation, association, visualization, and prediction. However, before we gain information from text, we need to gather the information and simplify it. And the procedure of that is called text pre-processing.4
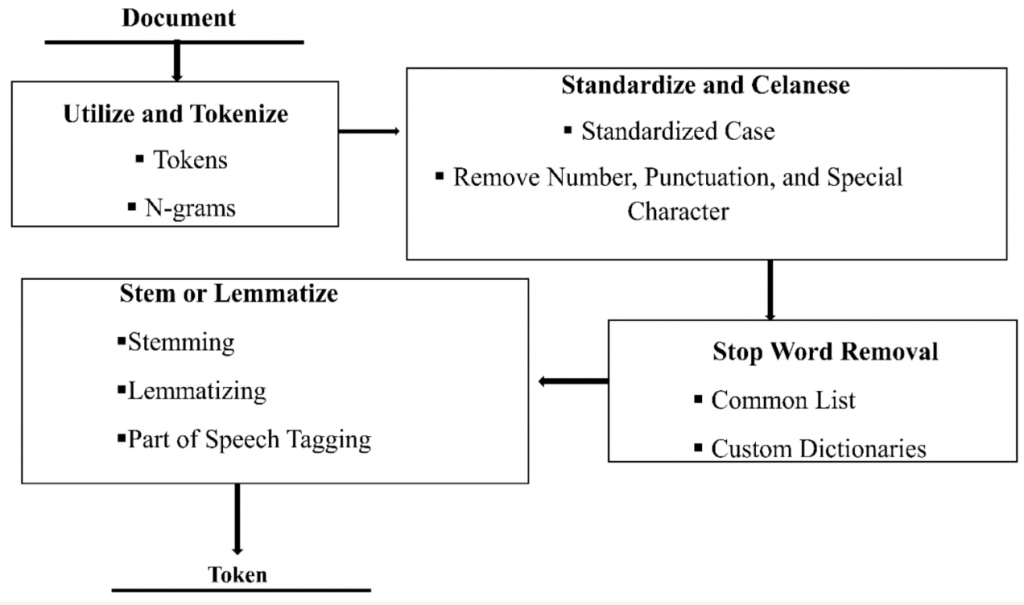
In general, text pre-processing removes unnecessary information from the raw text by tokenization, standardization, and cleansing and stop word removal and stemming or lemmatization. The image below depicts the text pre-processing procedure. And we need to know that this procedure is the most crucial step before we go into the text mining procedure.4
In the text mining procedure, we can use 4 techniques: word cloud, sentiment analysis, classification, and clustering. The image below shows the popular text mining procedure.4
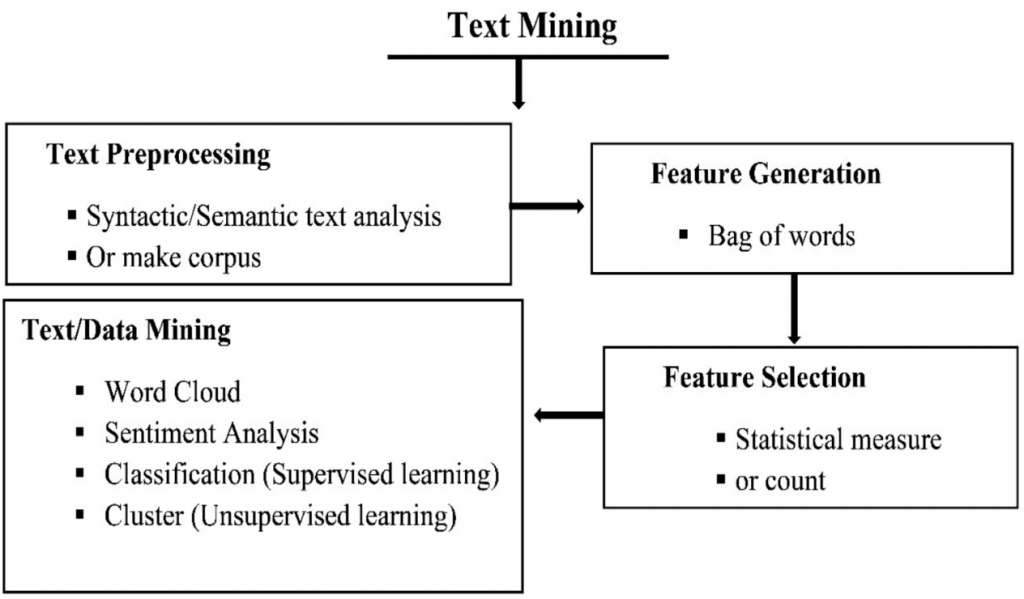
Word cloud and sentiment analysis are the most well-known techniques in the text mining procedure4 and the technique I did in my DataCamp project was sentiment analysis. And for that reason, I will be using sentiment analysis for my idea. However, what exactly is sentiment analysis?
Essentially, sentiment analysis is a procedure to detect or define eight primary emotions of humans and animals, which is defined by the eminent psychologist Robert Plutchik through words from the text. Those primary emotions are anger, fear, sadness, disgust, surprise, anticipation, trust, and joy. In addition, we also can detect the polarity of a document, particularly positive and negative explication.4
The Idea
In my idea, I wanted to know the characteristic of hoax information regarding health issues on the Twitter platform by analyzing data from Twitter with specific keywords. Yet, the specific keywords regarding health issues are still being considered. However, I have two examples, which are Monkeypox and Covid-19 since those health issues are the most popular right now.
To be continued
References
- Vuković, M., Pripužić, K., Belani, H. (2009). An Intelligent Automatic Hoax Detection System. In: Velásquez, J.D., Ríos, S.A., Howlett, R.J., Jain, L.C. (eds) Knowledge-Based and Intelligent Information and Engineering Systems. KES 2009. Lecture Notes in Computer Science(), vol 5711. Springer, Berlin, Heidelberg. [Link]
- Prasetijo, A. B., Isnanto, R. R., Eridani, D., Soetrisno, Y. A. A., Arfan, M., & Sofwan, A. (2017). Hoax Detection System on Indonesian News Sites Based on Text Classification using SVM and SGD. Int. Conf. on Information Tech., Computer, and Electrical Engineering (ICITACEE). Semarang, Indonesia. [Link]
- Dizikes, P. (2018). Study: On Twitter, false news travels faster than true stories. MIT News. [Link]
-
Hossain, A., Karimuzzaman, Md., Hossain, Md. M., & Rahman, A. (2021). Text Mining and Sentiment Analysis of Newspaper Headlines. Information, 12(10), 414. MDPI AG. [Link]